
Tomb Raider: Definitive Edition

Miranda Keyes

Lara

Lee & Clementine
Lee & Clementine

Action Movie Kid
Colonización Cultural: La Yapa
Una prueba de que la colonización cultural no existe.
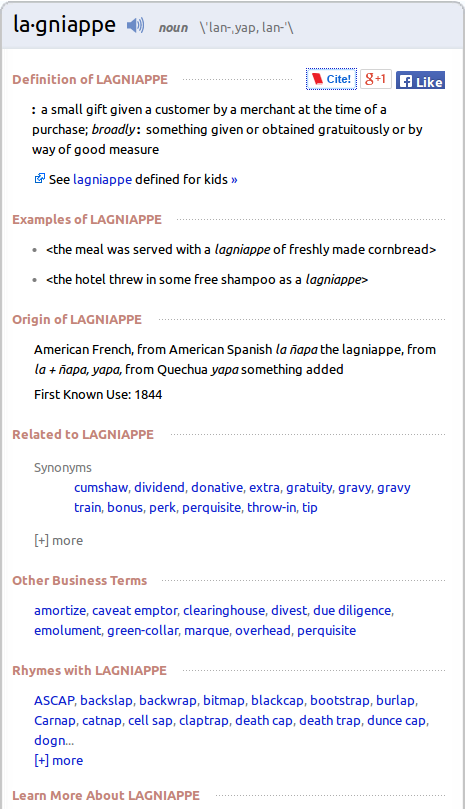
Definición de lagniappe en el diccionario Merrian-Webster: yapa.
Si realmente existiera una colonización cultural o imperialismo lingüístico no se explica cómo una palabra quechua como «yapa» se incorporó al inglés. Los defensores de la lengua ante el avance del inglés por favor miren para otro lado.
Cómo Manejar el TrustStore de Java sin Volverse Loco

KeyStore Explorer 5.1
Para trabajar con certificados SSL, key stores y trust stores las herramientas de línea de comando son bastante áridas. Por suerte existe KeyStore Explorer. Me animaría a decir que tiene todo lo necesario, pero lo más importante es que es muy fácil de usar, tiene ayuda integrada y muchas opciones.
Muy poca gente menciona esta herramienta cuando se trata de orientar a la gente que tiene que hacer alguna operación con claves o certificados SSL, pero es muy recomendable.
Principalmente convierte en transparente un proceso que suele ser bastante opaco si no se sabe bien lo que se está haciendo con la herramienta keytool.
Hashes y Ataques de Denial of Service: Java, Python, Ruby, PHP y ASP
En casi todos los lenguajes de programación hay algún tipo de estructura de datos como una tabla hash (llamados por ejemplo hash map, hash table, dictionary, entre otros). Básicamente permiten asociar un valor a una clave y posteriormente obtener dicho valor proporcionando la clave en un tiempo constante sin importar cuantas claves haya en la estructura.
Para lograr que la búsqueda sea en tiempo constante, los valores se almacenan en una posición de la tabla según el valor de hash de su clave.
Es posible, aunque poco probable, que dos claves distintas generen una colisión, es decir que dos claves distintas generen el mismo valor de hash y por lo tanto dos valores deban guardarse en una misma posición. Una forma de hacer eso es tener una lista de valores en lugar de solo un valor en cada posición. Luego de identificar la posición mediante el valor de hash se hace una búsqueda secuencial entre todos los elementos de esa lista.
Un ataque de denegación de servicio mediante hash o Hash DoS consiste en explotar esas colisiones para hacer que la lista de valores sea muy larga y se requiera mayor tiempo de procesamiento para buscar, agregar y eliminar elementos.
En lenguajes usados para aplicaciones Web como PHP, Python, Java, Ruby o ASP, los valores ingresados mediante un formulario web son cargados en tablas hash para su posterior procesamiento y por eso todos resultaron vulnerables a esos ataques.
En esta transparencia de PHP se muestra un requerimiento POST creado para explotar esta vulnerabilidad: http://talks.php.net/show/phpuk2012/14
Existen tres formas de atacar el problema, con diferentes grados de éxito y complicación.
- PHP, ColdFusion y ASP optaron por «controlar los daños» limitando a 1.000 la cantidad de valores de entrada que pueden llegar en un requerimiento POST. En el php.ini de PHP 5.3.9 en adelante hay una configuración max_input_vars=1000.
- Python [http://bugs.python.org/issue13703], Ruby y Java 7 adoptaron una mejora en el algoritmo de hash para dificultar la generación de colisiones incorporando números pseudoaleatorios en su cálculo.
- Java 8 incorpora un árbol balanceado para almacenar todos los valores cuyas claves tengan el mismo hash [http://openjdk.java.net/jeps/180]. De esa forma con miles de millones de valores, apenas requeriría 50 operaciones para resolver la búsqueda.
Es importante destacar que la solución adoptada por PHP, ASP y ColdFusion de limitar la longitud de la entrada no resuelve por completo el problema ya que por ejemplo si se envía un hash con muchas colisiones dentro de un string JSON, pueden ser menos de 1.000 parámetros e igual disparar el problema. Básicamente las aplicaciones deben igualmente verificar internamente los datos que reciben.
La alternativa de mejorar la función de hash es un bastante más robusta, aunque puede ser más difícil de implementar. En algunos lenguajes podría tener un impacto negativo en la performance o requerir cambios en algún comportamiento ya definido.
La solución elegida en Java 8 (y que vuelve atrás los cambios incorporados en Java 7 para tratar este mismo problema) es muy robusta y elimina la causa fundamental del problema.
TIFF vs. PNG vs. JPEG 2000: Compresión de Imágenes sin Pérdida
Cuando se decide digitalizar fotos para conservarlas lo ideal es guardarlas en un formato sin pérdida de información para retener el detalle tal como se pudo obtener del escáner. La desventaja es que ocupan mucho más espacio que un JPEG.
Muchos prefieren directamente un formato sin compresión como TIFF sin comprimir, pero existen formatos de compresión sin pérdida que permiten ahorrar espacio de almacenamiento sin un costo significativo.
El formato TIFF admite diferentes tipos de compresión, luego están el PNG y el JPEG 2000.
Para comparar armé un grupo de 356 imágenes color de 24 bits y aproximadamente de 3.200 por 2.000 pixeles que totalizan 6.164.301.370 bytes sin comprimir (TIFF sin compresión).
Las comprimí a
- JPEG 2000 sin pérdida,
- a PNG
- a TIFF con compresión LZW
- y a TIFF con compresión Zip.
Estos fueron los comandos que usé.
JPEG 2000: mogrify -format jp2 -define jp2:rate=1.0 -define jp2:mode=int -depth 8 -define jp2:tilewidth=256 -define jp2:tileheight=256 -path /home/user/jp2-lossless/ /home/user/test/*.tif
TIFF LZW: mogrify -format tif -depth 8 -compress LZW -path /home/user/tiff-lzw/ /home/user/test/*.tif
TIFF Zip: mogrify -format tif -depth 8 -compress Zip -path /home/user/tiff-lzw/ /home/user/test/*.tif
PNG: mogrify -depth 8 -path /home/user/png-9/ -format png -quality 9 /home/user/test/*.tif
Los resultados.
| Formato | Bytes | MB | % del MAX | % del MIN |
| TIFF Zip | 3.142.359.890 | 2.996,79 | 50,98% | 118,91% |
| PNG 9 | 2.750.377.023 | 2.622,96 | 44,62% | 104,07% |
| JPEG 2000 | 2.642.693.320 | 2.520,27 | 42,87% | 100,00% |
| TIFF LZW | 3.520.584.906 | 3.357,49 | 57,11% | 133,22% |
| TIFF sin comprimir | 6.164.301.370 | 5.878,74 | 100,00% | 233,26% |
JPEG 2000 da la máxima compresión sin pérdida, aunque PNG se acerca muchísimo. JPEG 2000 permite ahorrar tan sólo un 1,75% más que PNG.
En un análisis foto por foto PNG comprimió más que JPEG 2000 en 36 casos y menos en 320 casos.
Si se incorporan al análisis otros factores como disponibilidad de herramientas, soporte del formato a futuro y el tiempo de compresión y descompresión, hay que destacar algunas cuestiones.
- No todas las herramientas leen todas las combinaciones de TIF con sus diferentes formatos de compresión. Es por eso que la Biblioteca del Congreso y otras instituciones recomiendan sólo usar TIFF sin comprimir para fotos.
- JPEG es todavía un formato nuevo y por lo tanto las herramientas son nuevas. Es común encontrar problemas con algunos archivos o con la disponibilidad de herramientas en algunas plataformas. El soporte debería mejorar con el tiempo, pero al ser un formato complejo el avance es lento.
- JPEG 2000 requiere cálculos más complejos y por lo tanto requiere mayor cantidad de procesamiento para comprimir y descomprimir las imágenes. Las distintas variantes de TIFF y PNG no requieren tanto procesamiento y son más rápidas.
- PNG es un estándar ISO público y está respaldado por la W3C que es la organización que rige los estándares de la Web y está implementado en todos los navegadores (incluso en los móviles).
- TIFF es un estándar público, pero no es ISO sino que es un estándar de Adobe (los dueños del Photoshop). Tiene muchas implementaciones y extensiones no estandarizadas.
- JPEG 2000 también es un estándar ISO, pero incorpora varias patentes que podrían implicar un costo por su uso en algún momento. En cambio PNG no está alcanzado por patentes.
